Research Software London is a community to support
the use and development of research software in London and the South East.
Since 2019, RSLondon has run a number of
Software Carpentry workshops to
teach introductory computing skills to researchers. ITSR have been involved
in these efforts, providing instructors and helpers at each of these workshops.
When it comes to picking a distribution, Python programmers are spoilt for
choice. We're going to compare two of the most popular (CPython and Anaconda)
and one that promises big performance improvements with relatively little
hassle (Intel Distribution for Python).
The information in this article is now outdated, please see
docs.hpc.qmul.ac.uk/apps/ml/tensorflow/
for recent documentation regarding TensorFlow installation and usage.
In this tutorial we'll be showing you how to run a
TensorFlow job using the
GPU nodes on the Apocrita HPC
cluster. We will expand upon the essentials provided on the QMUL HPC
docs site, and provide more explanation of the process.
We'll start with software installation before demonstrating a simple task and
a more complex real-world example that you can adapt for your own jobs, along
with tips on how to check if the GPU is being used.
Jigsaw puzzles proved wildly popular during lockdown, but they weren't all
done on the dining room table on rainy afternoons. The puzzle faced by
researchers from the School of English and Drama (SED), lead by
Dr Richard Coulton and in
collaboration with the Natural History Museum, was
to piece together a set of beautiful botanical watercolours brought back from
China by the East India Company surgeon James Cuninghame. Cuninghame
purchased these works, by an unknown local artist, in Xiamen in 1699. Sometime
in the first half of the eighteenth century, perhaps because of their large
size, these watercolours were cut up and glued into what you ungenerously,
call a scrap book. The British Library has lovingly digitised this book in a
series of
publicly-available
high resolution images funded by Oak Spring Garden Foundation, who also
sponsored the current project.
On Apocrita we can use OpenMP to execute code on GPU devices. This post looks
at how to compile such programs and submit them to run on the GPU nodes. The
post assumes that you have code, already developed and tested, which is ready
for deployment, and that you have been granted access to the GPU nodes.
The Apocrita scratch storage
is a high performance storage system designed for short-term file storage,
such as working data. We recently replaced the hardware that provides this
service, and expanded the capacity from 250TB to around 450TB. This article
will look at the recent changes, and suggest some best practices when using
the scratch system.
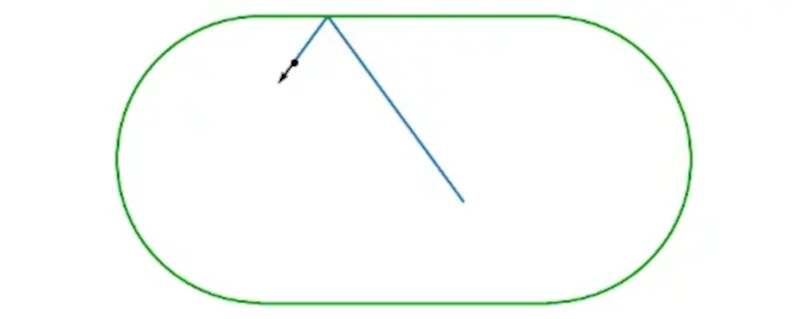
A little while ago, we were approached by a researcher from the School of
Mathematical Sciences with the classic request of "I'd like my code to run
more quickly". They were simulating a ball bouncing around a billiard table
over the course of millions of collisions and analysing patterns in the path
of the ball (this type of problem is known generally as dynamical billiards).
The Intel Parallel Studio XE Cluster Edition 2020 update 4 suite is now
installed and available on Apocrita. This release will be the last of the
Parallel Studio releases we support, as Intel is moving to its
oneAPI model of bundling.
Visual Studio Code (VS Code) is an open-source and lightweight text editor
from Microsoft, and distinctly different from Visual Studio.
In this short tutorial we aim to set up VS Code for remote interfacing and
development on Apocrita, to edit, save, and manipulate our files and
directories.
User-defined data types in Fortran may have parameters which control certain
aspects of their definition. In this post we look at what these parameterized
types are, how they are used and what benefits they may offer to the
programmer.