A Large Scale Ancestry Study | Living with Machines¶

Living with Machines is a funded project at The Alan Turing Institute (aka the Turing), bringing together academics from different disciplines, to answer research questions such as how did historical newspapers tell the political landscape, how were accidents in factories reported, how did road and settlement names change, how did people change occupations during the industrial revolution...
Millions of historical sources were digitised, paving opportunities to analyse them using modern technologies. Sources, such as newspapers, maps and census, are available (some publicly) and crucial to understanding life during the industrial revolution. Modern technologies allow us to process much larger datasets, more than a historian could by themselves, revealing more secrets hidden behind these sources.
In my secondment, I was assigned to work on historical census data with software engineers and historians. This blog describes my time at the Turing, a chance to reflect on working in the interdisciplinary field of digital humanities.
Looking Into Our Ancestors¶
In the UK, from the late 1800s, a census was taken every 10 years, recording people's names, ages, sexes, addresses, birthplaces and occupations. They are held by The National Archives and were digitised by Findmypast. In addition, they were cleaned and coded and made mostly available to the public, known as the Integrated Census Microdata (I-CeM). However, a special license, from the UK Data Service, is required to access names and addresses. They are important to track individuals from one census to the next. This is called record linkage.
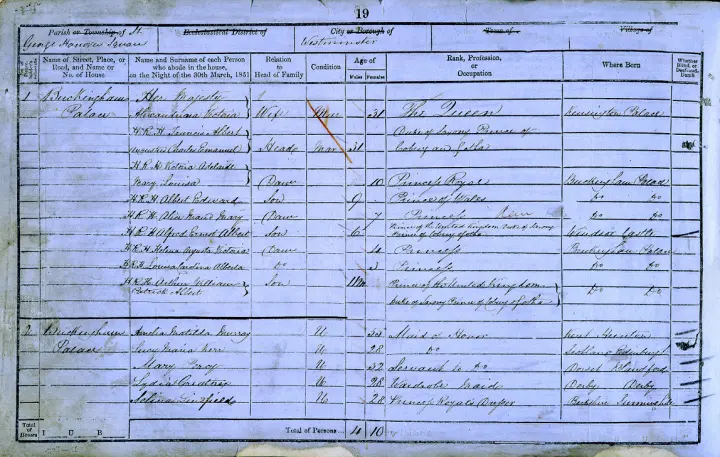
Figure 1: A page from the 1851 census - Buckingham Palace [source]
On a microscopic level, this allows us to track our ancestors and investigate family history, for example, whether they continued working in their family business.
However, on the macroscopic level, we can pull together all of the record linkages and study how the population evolve. For example, we can study how the population changed occupations, not just individuals, as new machines were introduced in manufacturing. We may also observe large-scale migration into cities to seek employment opportunities.
We were tasked to implement or build upon existing software to do record linkage on the historical censuses. The results from the record linkage allow historians to draw findings about occupations, for the population, during the industrial revolution.

Figure 2: A Sankey diagram showing the distribution of London workers' occupations in 1891 who are now skilled metal workers in 1901
Cleaning Data Physically and Digitally¶
With millions of unique combinations of forenames, surnames and birthplaces, I thought this shouldn't be too hard to identify individuals. However, we faced many problems. The most common being people's names and birthplace abbreviations were not consistent from census to census. For example, both the county of Oxfordshire and the city of Oxford may be abbreviated to Oxon. In addition, women also change their surnames after marriage, losing another token to uniquely identify an individual.
We've also found it was not uncommon for additional information, for example
BRITISH SUBJECT, to be included in the birthplace field. They will need to be
stripped or ignored to be processable. Comparing birthplaces should be done
using only, and only, birthplaces. Providing additional irrelevant information
may be confusing.
Another problem with birthplaces is that location names may change in the next census. This has to be taken into account in our record linkage.
There were problems outside the scope of the project too, for example, a census entry may be damaged beyond recognition or an error when transcribing entries.
Securing Commercial Data¶
Due to commercial interest, the census data must be secured and never enter the public. With that in mind, most of our work was done in a safe haven, a server where we can work with the census data but cannot connect to the internet.
The safe haven, at the Turing, is an Azure instance. This can only be remotely connected through a VPN from approved managed computers. In my case, I was lent a managed Chromebook with all the software and settings set up. In addition to the Chromebook, I must enter my password and a token sent to my mobile phone to have access to the safe haven. This is a total of three factors in the authentication, a password, my mobile phone and the Chromebook!
There were a few hurdles when working in the safe haven. Without internet
access, installing Python packages have to be done outside the safe haven and
imported into the safe haven with administration approval. It isn't as simple as
a pip install anymore.
In addition, lugging the Chromebook around in addition to my work laptop does take a toll on my shoulders in my commute, especially during tube strikes. Meetings also become unwieldy, with each person with two laptops at the table!
While it is understandable to have security measures to protect commercial data, they sometimes can be a hindrance both on-screen and off-screen. Thus it was important to plan my workflow and habits to work with the safe haven.

Figure 3: My work laptop and Chromebook to access the safe haven
For further information on how the Turing implements their safe haven, please visit their website here.
Being Agile¶
I entered the census project about 3 months after it started, with 12 months of part-time work left of funding. In my opinion, it looks like we've adopted an agile workflow because working software was there when I started. After spending 3 months understanding the software, we were tasked to improve it and prepare it for a public release by the time funding runs out. By adopting an agile workflow, people can enter (like myself) and leave during the project.
Some of my contributions include providing coordinates to birthplaces. Should a birthplace settlement change name or boundaries between censuses, we can make record linkages depending on how close the birthplace coordinates are.
Because we cannot share real historical census data, I have also written software which creates synthetic data, emulating the historical census data. This is useful for users outside of the Turing to use and test our record linkage software, making it more accessible in a public release. Synthetic data can also be used to evaluate our record linkages as we can assess which links are correct or incorrect.
We have also improved the existing code by refactoring it using class structures.
The Weakest Link¶
A novice may mistakenly claim that the record linkage code is improved if more links are made. However, this doesn't acknowledge that some of the links made may be false or incorrect. A monkey can claim 100% of records linked by drawing random lines between every record but, almost surely, all of them will be false.
We certainly want as many links as possible, but the more links we make, the more likely false links occur. It is then important to report the occurrence of false links in any evaluation of record linkages. For example, we can report or control a metric called the false discovery rate (FDR), which is the proportion of links we've made which are false.
For population-size studies, we want the FDR to be low to avoid false links but high enough to get links to represent the population. On the other hand, if historians are interested in writing a story behind some of the links, we can afford to have a lower FDR to have fewer links but more unlikely they will be false. They certainly wouldn't need thousands of links for that purpose. It is interesting to observe how controlling the FDR can vary from purpose to purpose, discipline to discipline.
We've used two ways to report the FDR. One is to create synthetic census data using a model and we perform our record linkage on that. Because we know the model, we can assess which links are true and which are false on a large scale. However, the reported FDR may have some biases as our model will not reflect the actual historical census exactly.
Another way to report the FDR is to have historians assess a sample of the links themselves. With their expertise, they can also investigate the scanned census on Findmypast to look for errors not picked up by our record linkage software. This will accurately report the FDR but at a cost of variance as historians only have a limited time to look through a handful of record links.
Pythons Come in Different Shapes and Sizes¶
One thing I've noticed, when working in an interdisciplinary field, is that the
expertise in Python does not just vary in depth but the breadth too. For
example, I usually contain my Python environments
using Apptainer
or virtualenv and install packages using pip. But I have encountered various
managers such as conda, anaconda and poetry in this project. I have also
noticed the use of Jupyter notebooks and pandas data frames is a lot more than
what I'm used to.
I've learnt that with such an interdisciplinary field, the use of Python and how it is taught varies dramatically. As software engineers, it is important to respect that and to cater to it to make our code to be as accessible as possible.
Conclusion¶
It was a pleasure working in an interdisciplinary field and collaboratively. Working with historical census data has allowed me to apply my skills in other fields and experience a range of breadth and depth of expertise from colleagues.
With an agile workflow in this project, I've managed to enter the project during its development and make improvements to existing software for record linkage.
I have mentioned some lessons learnt already. But I would also like to add that it's important to keep feasibility in mind during a project, especially when there is a time limit to projects. I find that setting small progress goals, for example on GitHub issues, makes me time manage my tasks well towards the end goal. I also find that paired or collaborative programming is helpful to keep us on a shared path, rather than getting carried away when exciting new ideas pop up in our heads.
I am thankful to work closely with Emma Griffin, Timothy Hobson, Jon Lawrence, Joshua Rhodes and Guy Solomon. I would also like to thank Ruth Ahnert, David Beavan, Léllé Demertzi and Daniel Wilson for welcoming me into the project.