A look at the Grace Hopper superchip¶

NVIDIA recently announced the GH200 Grace Hopper Superchip which is a combined CPU+GPU with high memory bandwidth, designed for AI workloads. These will also feature in the forthcoming Isambard AI National supercomputer. We were offered the chance to pick up a couple of these new servers for a very attractive launch price.
The CPU is a 72-core ARM-based Grace processor, which is connected to an H100 GPU via the NVIDIA chip-2-chip interconnect, which delivers 7x the bandwidth of PCIe Gen5, commonly found in our other GPU nodes. This effectively allows the GPU to seamlessly access the system memory. This datasheet contains further details.
Since this new chip offers a lot of potential for accelerating AI workloads, particularly for workloads requiring large amounts of GPU RAM or involving a lot of memory copying between the host and the GPU, we've been running a few tests to see how this compares with the alternatives.
The servers are not attached to Apocrita currently, as it is an evaluation system. In particular, the IBM parallel storage system currently does not support ARM processors in production systems.
PyTorch resnet50 benchmark¶
Our first test compares performance of the PyTorch ResNet50 training recipes published by NVIDIA, which uses the ImageNet 2012 dataset (150GB in size). Training was run for 90 epochs, which takes approximately 1 hour.
Since the hardware is very new, it was necessary to use a container from the NVIDIA NGC in order to work fully, as opposed to installing via conda. For consistency, we used the container approach for both ARM and Intel node types, and copied the ImageNet dataset to a local SSD to remove potential variance due to load on the shared storage system.
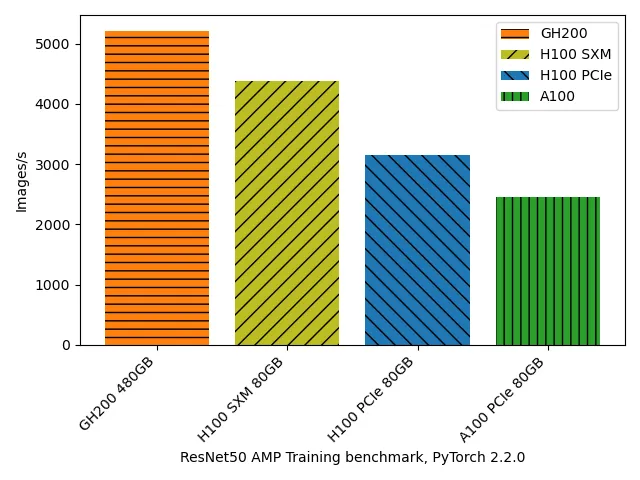
ResNet50 Mixed Precision (AMP) Training benchmark, single GPU¶
| GPU Device | PyTorch version | Batch Size | GPUs used | Images/s |
|---|---|---|---|---|
| A100-PCIE-80GB | 2.2.0a0+81ea7a4 | 256 | 1 | 2451.59 |
| H100 PCIe 80GB | 2.2.0a0+81ea7a4 | 256 | 1 | 3147.54 |
| H100 SXM 80GB | 2.2.0a0+81ea7a4 | 256 | 1 | 4380.87 |
| GH200 480GB | 2.2.0a0+81ea7a4 | 256 | 1 | 5215.58 |
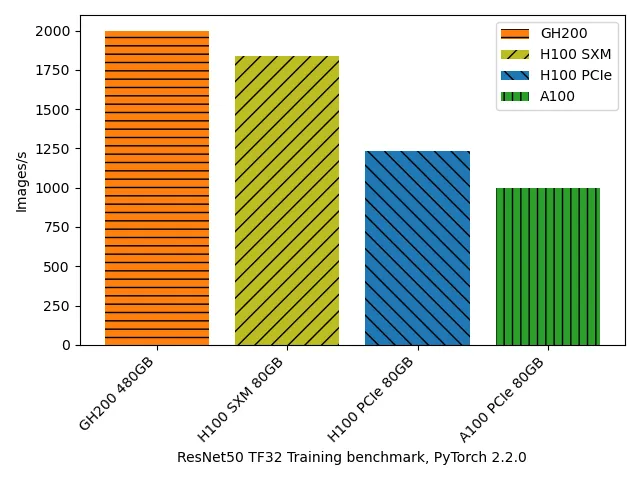
ResNet50 TF32 Training benchmark, single GPU¶
| GPU Device | PyTorch version | Batch Size | GPUs used | Images/s |
|---|---|---|---|---|
| A100-PCIE-80GB | 2.2.0a0+81ea7a4 | 256 | 1 | 1003.25 |
| H100 PCIe 80GB | 2.2.0a0+81ea7a4 | 256 | 1 | 1233.08 |
| H100 SXM 80GB | 2.2.0a0+81ea7a4 | 256 | 1 | 1839.38 |
| GH200 480GB | 2.2.0a0+81ea7a4 | 256 | 1 | 2000.37 |
FLAME GPU benchmark¶
The FLAME GPU 2 benchmark is produced by the University of Sheffield and is a good example of an application that has high GPU utilisation but performs very little memory copying between host and GPU, so performance would be expected to be similar to a regular Intel GPU node with an SXM H100 GPU. Indeed, our results found that this was the case, and there was very little variation in any of the results.
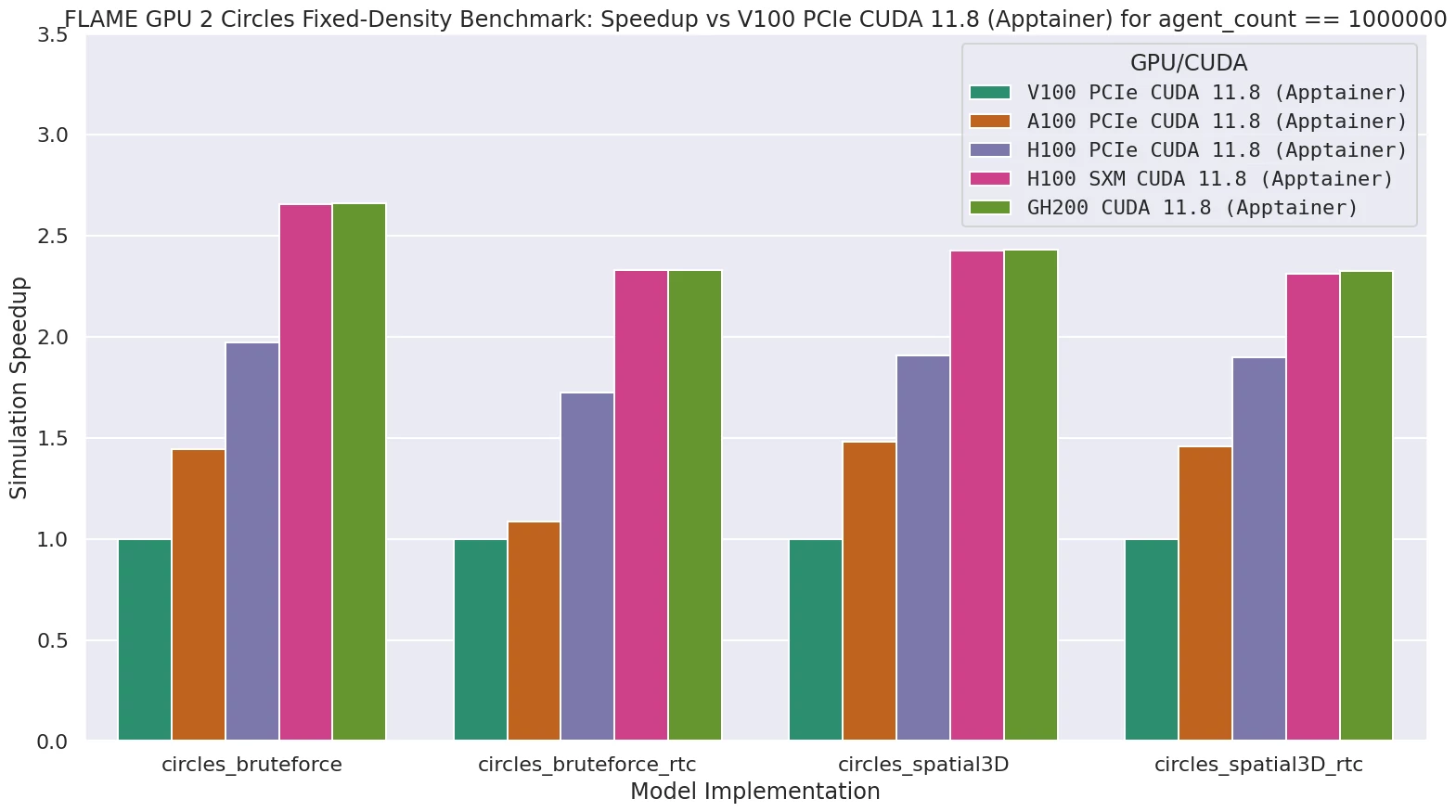
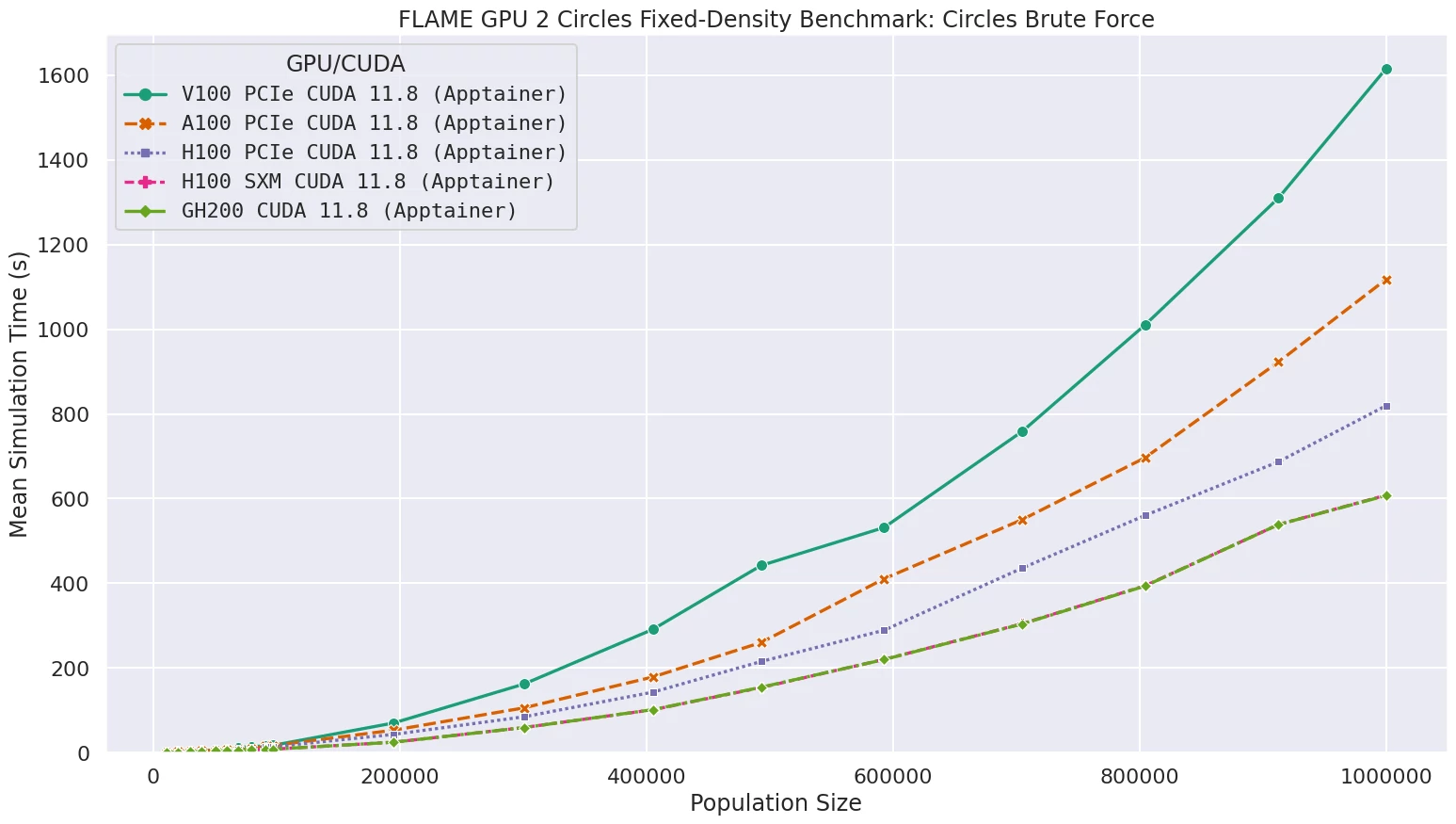 Results from FLAME benchmark showing performance consistent with H100 GPUs
Results from FLAME benchmark showing performance consistent with H100 GPUs
PyTorch MNIST example¶
Finally, we trained an ensemble of convolutional neural networks to predict handwriting using the MNIST dataset (64MB). Twelve bootstrap samples were used in bagging for the ensemble. For each bootstrap sample, twelve random parameters were investigated in 5-fold cross-validation to tune the parameters and the size of the network. In total, 720 networks were fitted in this procedure. Up to 1,000 channels in the convolution layer and 2,000 neurons in the hidden layer were investigated.
The GH200 provided a decent performance boost compared with the same code running on a single SXM H100 80GB in an Intel node. The chart also includes some much faster multi-node results which are part of a forthcoming blog post looking at parallel GPU workloads.
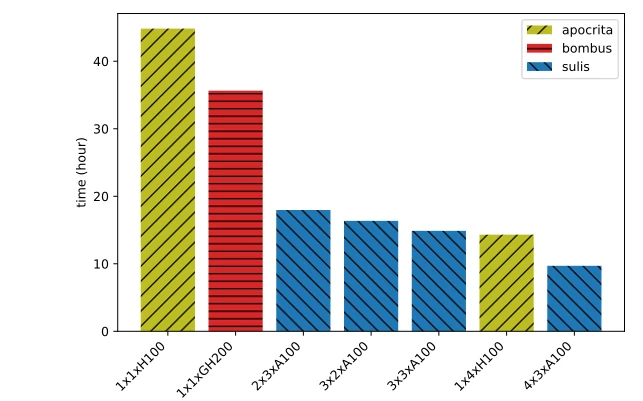
Results from real-world code running across single and multiple nodes and GPUs
Summary¶
Apart from the obvious issue of requiring ARM64 builds of code to run on the Grace Hopper superchip, it looks like an interesting prospect. In addition to the excellent performance we've observed, we look forward to also exploring multi-node performance via the ConnectX-7 network card (since we are limited to 1 GH200 per server), and larger jobs that don't fit on conventional GPUs. Our testing also showed that (at least for these workloads) the SXM H100 GPUs outperformed their PCIe equivalents by quite some margin - bigger than we had expected.