Simplification of parallel queues on Apocrita¶

We are simplifying the way that the multi-node parallel jobs are run on the cluster.
Currently, users wishing to run multi-node MPI jobs on the public queues must choose beforehand whether to run on the nxv parallel nodes or the sdv parallel nodes, and to configure the job accordingly for the number of cores on each type of node.
We have decided, after consultation with some of the heavier users of the parallel nodes, to make a single large pool of InfiniBand-connected parallel nodes by increasing the number of sdv parallel nodes from 14 to 32, while moving the nxv parallel nodes to the serial queues.
Having a single, larger non-blocking island of nodes will hopefully:
1) reduce queue waiting time for larger multi-node jobs due to now having a larger combined pool of parallel nodes to choose from.
2) reduce queue waiting time due to choosing "the wrong queue" i.e. situations where the nxv island is full, but sdv nodes are free, but you already committed to the nxv island in your submission script - we see this quite a lot.
3) easier transition between public/restricted nodes for users who have access to private sdv parallel nodes.
4) easier transition to any Tier2 services which have 24 core nodes, e.g. Thomas.
5) greater compatibility of compiled code, since all nodes in the pool have the same CPU architecture.
6) documentation for users will be easier to understand.
While the nxv nodes have more cores, the sdv nodes have shown to be faster in real-world tests for parallel jobs on a core-by-core comparison, and node-by-node comparison, as shown below:
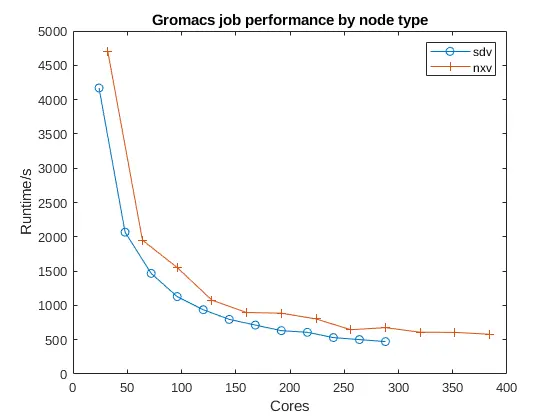
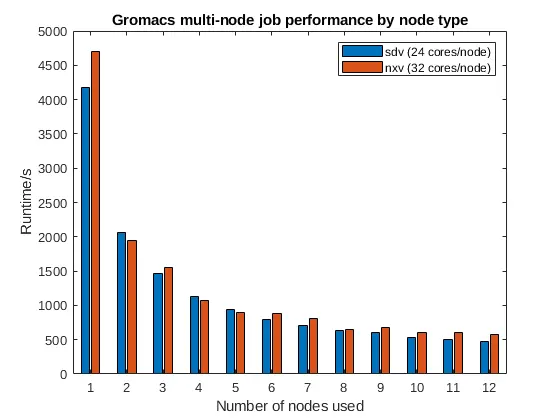
What do I need to do?¶
Any job scripts previously utilising -l ib=nxv in the job script will
typically now use -l ib=sdv-i instead, and the core count should be a
multiple of 24 (starting at 48 for multi-node jobs). We discourage single-node
jobs running on the parallel queues since these tend to block larger jobs from
running, and do not benefit from the InfiniBand low latency networking, meaning
they could be run elsewhere. Please refer to
our documentation which also
has example job scripts.
We have begun the transition process and have updated the documentation accordingly, including an announcement to the Apocrita users mailing list - please do get in touch if you experience any issues.