Performance testing with NVMe storage and Spectrum Scale 5¶
We have recently procured 120TB of NVMe based SSD storage from E8 Storage for the Apocrita HPC Cluster. The plan is to deploy this to replace our oldest and slowest provision of scratch storage. We have been performing extensive testing on this new storage as we expect it to offer new possibilities and advantages within the cluster.
We tested using the IO-500 benchmark which gives a good comparison of storage within HPC and supercomputers. This was presented at Supercomputing 2018 and where we achieved 19th place overall and 8th in the ten node challenge
We initially tested it using the same version of Spectrum Scale as we currently use on the Cluster (version 4.2.3-8) and these results are presented on the IO-500 website We have since tested it under under version 5.0.2-1 and have seen a significant improvement with this.
Due to the improved performance offered by 5.0.2-1, we have started the task of upgrading the cluster to this version and have delayed putting this new scratch into production until this is complete.
Method¶
The IO-500 tests are based on a series of 12 tests, each of which takes around 5 minutes and test different aspects of the storage.
This is then averaged to produce 3 numbers;
- bandwidth measured in (GB/s)
- an IOPS speed or the number of input output operations that can be done in a second, this measures how many different operations can be done in a second such as deleting, creating, files etc
- a score that is generated from both the above numbers
The tests are done in parallel over multiple nodes using MPI. They require a certain amount of tuning to get the sample size correct, and to ensure the runtime is long enough to get a valid result.
All the tests were conducted on 10 nodes so that they could be entered in the IO-500 10 node challenge and also as this maximized the available network bandwidth, as our new nodes are connected at 25Gb/s and the servers are connected via 2x100Gb/s each.
Due to a supplier issue, we were only able to test with a single 100Gb/s cable initially.
Results¶
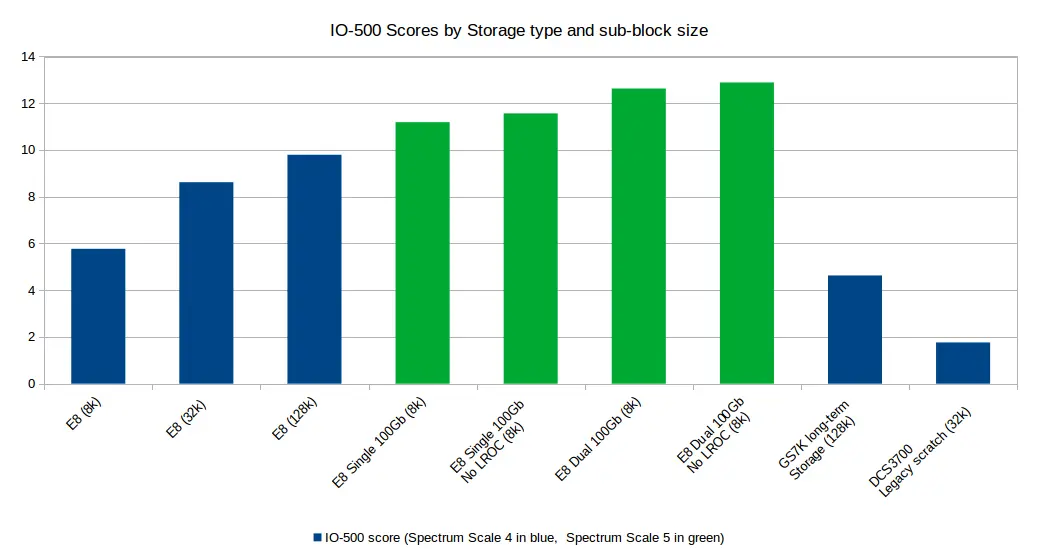
With Spectrum Scale version 4.2.3-8 we achieved a performance increase of 2GB/s and 5,000 IOPS by increasing block size. However with version 4.2.3-8 the larger sub-blocks mean that smaller files consume more space on disk than with Spectrum Scale 5.
Testing with Spectrum Scale 5 gained us an additional 1GB/s and 500IOPS. Our final test was done with LROC switched off and a second 100Gb/s cable added to the nodes to to connect them to our network.
| Filesystem | Spectrum Scale Version | Sub-block Size | Network | Bandwidth (GB/s) | IOPS (kIOPS) | Score |
|---|---|---|---|---|---|---|
| E8 Storage | 4.2.3-8 | 8k | 1 x 100GB/s to Servers | 1.60755 | 20.77076 | 5.77076 |
| E8 Storage | 4.2.3-8 | 32k | 1 x 100GB/s to Servers | 3.56631 | 20.8373 | 8.62046 |
| E8 Storage | 4.2.3-8 | 128k | 1 x 100GB/s to Servers | 4.31865 | 22.2083 | 9.79336 |
| E8 Storage | 5.0.2-1 | 8k | 1 x 100GB/s to Servers | 4.9833 | 25.1192 | 11.1882 |
| E8 No LROC | 5.0.2-1 | 8k | 1 x 100GB/s to Servers | 5.36317 | 24.933 | 11.5637 |
| E8 Storage | 5.0.2-1 | 8k | 2 x 100GB/s to Servers | 5.06971 | 28.2841 | 12.6299 |
| E8 No LROC | 5.0.2-1 | 8k | 2 x 100GB/s to Servers | 5.40544 | 30.721 | 12.8864 |
| GS7K Long Term Storage | 4.2.3-8 | 128k | 1 x 40GB/s to Servers | 1.27202 | 16.8452 | 4.62898 |
| DCS3700 Legacy Scratch | 4.2.3-8 | 32k | 1 x 40GB/s to Servers | 0.398526 | 7.80222 | 1.76335 |
Conclusions¶
LROC (Local Read Only Cache) is a Spectrum Scale feature to locally cache read operations to improve storage performance. Under certain workloads we observed no real benefits, and sometimes detrimental performance on compute nodes. We are therefore going to stop using it while we perform further tests with real-world applications. The workloads in question involve most tasks only reading a few files once. Other factors include: many fast SSD devices on the storage server are in fact faster than a local device, and that we are running on a fast low latency network where it is not significantly slower to fetch data over the network. It should also be noted that the main bulk storage already stores its metadata on SSD and hence should not be badly affected by this change.
Under Spectrum Scale 4 it was necessary to have large blocks for optimal RAID metadata operations, but this comes with the cost of wasting large amounts of space with smaller data files. The smaller sub-block in Spectrum Scale resolves much of this issue.
This is a continuing issue on our long-term storage and impossible to fix retrospectively without reformatting the filesystem, however the block size currently in use on the long-term storage is the best that is available in Spectrum Scale 4.2.3.
References¶
Title image: Isaac Smith on Unsplash